
Reimplementing “git clone” in Haskell from the bottom up
Stefan Saasen - March 2013 - @stefansaasen
- Reimplementing “git clone” in Haskell from the bottom up
Motivation
In order to give some structure to my ongoing investigation of git’s data structures, protocols and implementation I decided to re-implement git clone without using any of git’s plumbing commands or any of the existing git libraries. Along the way I tried to keep some implementation notes that should help to understand some of the building blocks required to replicate the clone functionality.
The git clone implementation that came out of this exercise is obviously of very limited practical value but required investigating some areas of git a git user is rarely exposed to.
The goal of this exercise was to go wide not deep. I will take certain shortcuts and omissions in order to implement a very minimal yet functional clone command.
The source code for what follows can be found here:
https://bitbucket.org/ssaasen/git-in-haskell-from-the-bottom-up
Note: There are a number of git related Haskell implementations and libraries already out there (e.g. gat - a git clone in Haskell or a number of git related packages on hackage) that I wasn’t interested in for the purpose of this exercise (learning from the bottom up). If you are after a Haskell git library those implementations are likely to be much better suited.
Overview
In order to implement git clone the following areas will be covered:
- The git protocol used to enable a git client to retrieve the required set of changes from a remote git server using a variety of transport mechanisms (native git protocol, ssh, http),
- the pack file format used to transfer the minimal amount of data from the server to the client (and more generally used for efficiently storing packed objects in repositories),
- the underlying object store that git uses to store commits, trees, tags and the actual file contents in the form of blobs
- and the index format used to track changes to the files in the working directory.
While some of those areas are covered elsewhere (e.g. the fantastic article Git from the bottom up covers the low level commands and the design of the git object store in great detail) this article tries to tie together the areas mentioned above, describes the tools used to investigate and verify the observed behaviour and to hopefully provide enough detail for the reader to re-implement the git clone command in a language of their choosing.
At the end of the article we will be able to execute:
$> hgit clone git://github.com/juretta/git-pastiche.git # Where hgit is the name for our custom binary
and we will get a valid git repository that can be used with the normal git client without making use of git or any git libraries for the actual clone and repository setup part. To keep the implementation focused, only the git:// transport protocol will be supported and the client will only do full, but not shallow clones.
In this article I’m going to use Haskell to implement the command, mainly to avoid simply re-implementing the main C or the popular Java based JGit implementations that already exist and to be able to show code examples in a very conscise way. If you are not familiar with Haskell, simply think of the code examples as condensed pseudo code.
The general approach was to investigate/reverse-engineer the actual behaviour when executing the clone command, gathering debug information by different means (e.g. git debug settings, packet capture, Dtrace), researching the protocols and data structures and reading the official documentation in the git source (esp. the Documentation/technical/*.txt files) and last but not least reading the actual git source.
The clone process
The clone operation goes through a set of stages.
It starts by invoking the command with a git URL (see the “GIT URLS” section in the “git clone” man page for the valid URL format):
$> git clone git://host:port/repo_path
- Parse the clone url to extract the host, port and repository path information.
- Connect to the git server via TCP using the native git transport protocol.
- Negotiate the objects that need to be transferrered from the server to the client. This includes receiving the current state of the remote repository (in the form of a ref advertisement) that includes the refs the server has and for each ref the commit hash it points to.
- Request the required refs and receive the pack file which contains all the objects that are reachable from the requested refs from the remote server.
- Create a valid git repository directory and file structure on disk.
- Store the objects and refs on disk.
- Populate the working directory with the files and directories that represent the tip of the ref the repository points to (taking into account symlink, permissions etc).
- Create the index file (staging area) that corresponds to that tip and the files on disk.
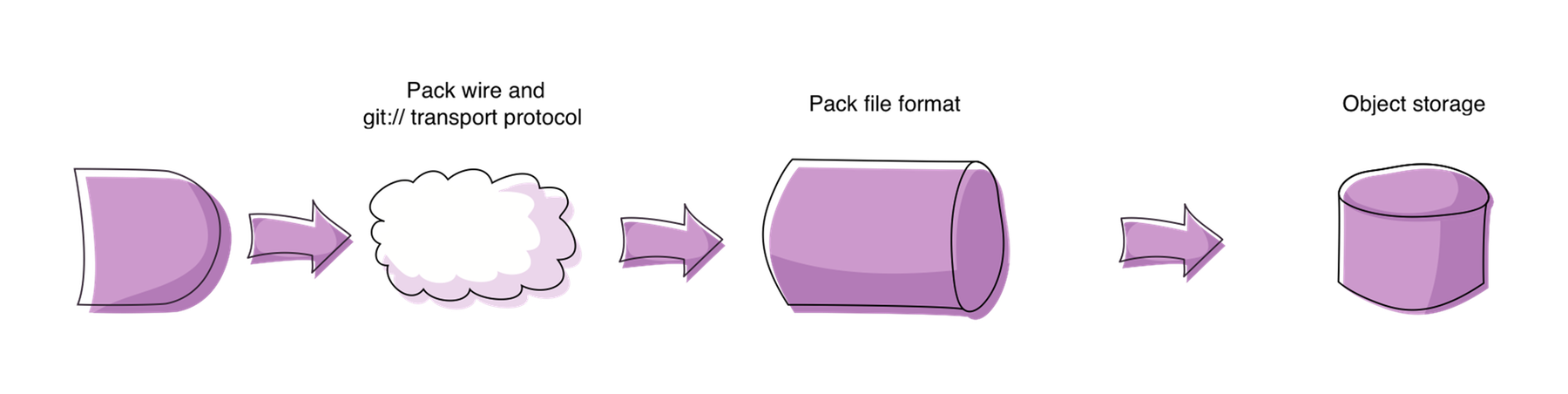
The article will loosely follow those steps and hence cover the following three broad sections:
- The git transport and pack wire protocol
- The pack file format
- The local object store and staging area
Git transport and pack wire protocol
In order to transfer the repository data (commits, tags, file contents, ref information) the git client and server processes negotiate the minimal amount of data required to update either the client (when fetching or cloning) or the server (when pushing).
git supports four main transport protocols to transfer the repository data: a local protocol if the source can be accessed via the local filesystem, and the following three protocols for remote access: SSH, a native git protocol and HTTP.
The remote transport protocols and the local protocol using the file:// URL scheme share the underlying approach of connecting the various *-pack commands being executed on the client and server. For a fetch operation this means connecting git fetch-pack on the client with git upload-pack running on the server. For a push operation the git send-pack command on the client will connect to the git receive-pack command on the server:
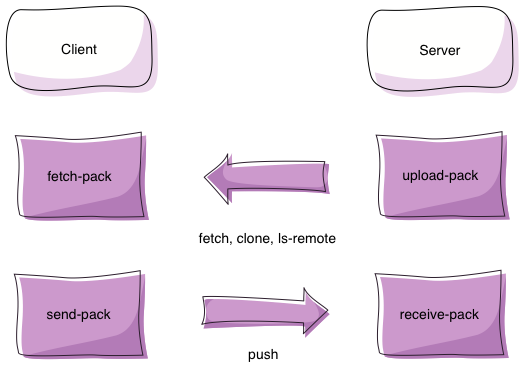
Note: For the clone operation instead of forking the git-fetch-pack command, clone invokes the fetch-pack.c#fetch_pack function directly via the transport.c layer to avoid one fork operation.
For easier testing and debugging the focus will be on the git protocol only, a simple, unauthenticated transport that uses full-duplex communication between client and server with the server usually listening on port 9418.
Transport protocol
Repository data exchange in git happens in multiple phases (detailed information can be found in the Documentation/technical/pack-protocol.txt file that is part of the git repository):
- Reference discovery
- Packfile negotiaton
- Packfile transfer
Reference Discovery
The reference discovery phase allows the client to detect what data the server has. The server provides this information in a list of refs that show for each ref that the server has (branches and tags) the most recent commit it has. This allows the client to determine if it is already up-to-date or what refs it needs to update the client side. The server response looks similar to this:
$> git ls-remote -h -t git://github.com/git/git.git | head -n 10
3a3101c62ecfbde184934f590bab5d84d7ae64a0 refs/heads/maint
21ccebec0dd1d7e624ea2f22af6ac93686daf34f refs/heads/master
2c8b7bf47c81acd2a76c1f9c3be2a1f102b76d31 refs/heads/next
d17d3d235a4cd1cb1c6840b4a5d99d651c714cc9 refs/heads/pu
5f3c2eaeab02da832953128ae3af52c6ec54d9a1 refs/heads/todo
d5aef6e4d58cfe1549adef5b436f3ace984e8c86 refs/tags/gitgui-0.10.0
3d654be48f65545c4d3e35f5d3bbed5489820930 refs/tags/gitgui-0.10.0^{}
33682a5e98adfd8ba4ce0e21363c443bd273eb77 refs/tags/gitgui-0.10.1
729ffa50f75a025935623bfc58d0932c65f7de2f refs/tags/gitgui-0.10.1^{}
ca9b793bda20c7d011c96895e9407fac2df9648b refs/tags/gitgui-0.10.2
Note: git ls-remote can be used to list references in a remote repository. This happens to be the same remote lookup of refs that occurs during the initial clone phase 1 (this is called the ref advertisement or reference discovery step).
Capabilities
As part of the reference discovery, client and server exchange information about capabilities the server supports. The client can then request certain capabilities to be in effect for the subsequent communication.
The capabilites are communicated as part of the first ref the server returns, separated from the SHA1, ref name pair by a \NUL byte:
3b1031798a00fdf9b574b5857b1721bc4b0e6bac HEAD\0multi_ack thin-pack side-band side-band-64k ofs-delta shallow no-progress include-tag multi_ack_detailed agent=git/1.8.1
The capabilities are described in detail in Documentation/technical/protocol-capabilities.txt and will be explained later on when they become relevant for the implementation.
Packfile negotiation
After reference and capability discovery, client and server try to determine the minimal packfile required for the client or server to be updated.
In the simplest scenario of a full clone, the client requests all refs and all the required objects the server has. For subsequent updates (e.g. fetch), the client not only defines what it wants, but tells that server what refs it has so that the server can determine the minimal packfile to send down to the client.
Packet line format
git’s protocol payload makes extensive use of the so called packet line (or pkt-line as used in the technical documentation) format. A pkt-line is a variable length binary string with the length encoded in the first four bytes of the pkt-line.
Example:
003f3b1031798a00fdf9b574b5857b1721bc4b0e6bac refs/heads/master\n
The first four bytes 003f are the length of the entire string (including the leading 4 length bytes) in hexadecimal (003f hex = 63 dec).
This can be implemented as follows (for avid Haskellers: I’m trying to avoid pointfree style for the examples in this text):
-- Create a packet line prefixed with the overall length. Length is 4 byte, hexadecimal, padded with 0
pktLine :: String -> String
pktLine msg = printf "%04s%s" (toHex . (4 +) $ length msg) msg
The pkt-line with length 0, i.e. 0000 is called the flush-pkt. A special case packet line that is used to signal that an agreed upon handover point in the communication exchange is reached.
The following table (taken from Documentation/technical/protocol-common.txt) shows a few pkt-line examples:
| pkt-line | actual value |
|---|---|
| “0006a\n” | “a\n” |
| “0005a” | “a” |
| “000bfoobar\n” | “foobar\n” |
| “0004” | ”” |
Client - Server exchange
To get an intuition for how the git protocol works, it’s best to try and observe the communication between client and server.
A simple git server can be started by using the following command in the parent directory of one or more git repositories:
$> cd /path/to/git/repos # there are 3 git repositories here
$> ls
git-bottom-up spy zlib
$> git daemon --reuseaddr --verbose --base-path=. --export-all
[39932] Ready to rumble
--base-path=.will map clone attempts usinggit://example.com/helloto the path./hello--export-allenables cloning from all directories that look like git repositories. Otherwisegit daemonverifies that the directory has the magic filegit-daemon-export-okbefore exporting any repository data. See git-daemon for further information.
With the git server running and having access to an existing git repository (which should be a bare repository without a working copy) we can now observe the exchange between client and server.
$> export GIT_TRACE_PACKET=1
$> git ls-remote git://127.0.0.1/git-bottom-up
packet: git> git-upload-pack /git-bottom-up\0host=127.0.0.1\0
packet: git< 3b1031798a00fdf9b574b5857b1721bc4b0e6bac HEAD\0multi_ack thin-pack side-band side-band-64k ofs-delta shallow no-progress include-tag multi_ack_detailed agent=git/1.8.1
packet: git< 3b1031798a00fdf9b574b5857b1721bc4b0e6bac refs/heads/master
packet: git< c4bf7555e2eb4a2b55c7404c742e7e95017ec850 refs/remotes/origin/master
packet: git< 0000
packet: git> 0000
3b1031798a00fdf9b574b5857b1721bc4b0e6bac HEAD
3b1031798a00fdf9b574b5857b1721bc4b0e6bac refs/heads/master
c4bf7555e2eb4a2b55c7404c742e7e95017ec850 refs/remotes/origin/master
Git has a number of debug settings that can be enabled by setting various environment variables. Setting GIT_TRACE_PACKET enables log output with information about the packets the client and server exchange. Apart from the GIT_TRACE_PACKET flag, the following environment variables are useful for debugging git commands:
GIT_TRACE_PACKET- show packet line informationGIT_TRACE- show general command execution debug informationGIT_CURL_VERBOSE- show curl debug information when using the http transport (includes HTTP headers)GIT_DEBUG_SEND_PACK- enable debug output inupload-packGIT_TRANSPORT_HELPER_DEBUG- enables debug output for the remote helpers
As can be seen in the above output, the GIT_TRACE_PACKET output shows the packet lines after decoding and stripping the length field. To see what is actually exchanged on the wire, it is necessary to capture the data packets using tools like Tcpdump, Wireshark or as used in this case: ngrep:
$> sudo ngrep -P "*" -d lo0 -W byline port 9418 and dst host localhost
interface: lo0 (127.0.0.0/255.0.0.0)
filter: (ip) and ( port 9418 and dst host localhost )
#####
T 127.0.0.1:49949 -> 127.0.0.1:9418 [AP]
0032git-upload-pack /git-bottom-up*host=127.0.0.1*
##
T 127.0.0.1:9418 -> 127.0.0.1:49949 [AP]
00ab3b1031798a00fdf9b574b5857b1721bc4b0e6bac HEAD*multi_ack thin-pack side-band side-band-64k ofs-delta shallow no-progress include-tag multi_ack_detailed agent=git/1.8.1
##
T 127.0.0.1:9418 -> 127.0.0.1:49949 [AP]
003f3b1031798a00fdf9b574b5857b1721bc4b0e6bac refs/heads/master
##
T 127.0.0.1:9418 -> 127.0.0.1:49949 [AP]
0048c4bf7555e2eb4a2b55c7404c742e7e95017ec850 refs/remotes/origin/master
##
T 127.0.0.1:9418 -> 127.0.0.1:49949 [AP]
0000
##
T 127.0.0.1:49949 -> 127.0.0.1:9418 [AP]
0000
This shows the actual exchange on the wire, with * as a placeholder for the non printable characters. Note: If you follow along, please update the interface to listen on, lo0 is the loopback interface on Mac OS X/BSD, it’s most likely lo on Linux - check with ifconfig.
To simulate low bandwidth/high latency scenarios which sometimes makes debugging easier, I found using dummynet via ipfw as a traffic shaping tool useful.
To limit the bandwidth to 20KByte/s for the git native protocol port 9418 use:
$> sudo ipfw pipe 1 config bw 20KByte/s
$> sudo ipfw add 1 pipe 1 src-port 9418
To remove the bandwidth limit afterwards:
$> sudo ipfw delete 1
This is useful to observe fast local executions that would otherwise be hard to capture.
With the necessary tooling to verify and observe the behaviour we can now look into implementing a client that speaks the git transport protocol.
Implementing ref discovery
To initiate the ref discovery, the client establishes a TCP socket connection to the server on port 9418 and issues a single command in packet line format.
The ABNF for the discovery request is:
git-proto-request = request-command SP pathname NUL [ host-parameter NUL ]
request-command = "git-upload-pack" / "git-receive-pack" / "git-upload-archive" ; case sensitive
pathname = *( %x01-ff ) ; exclude NUL
host-parameter = "host=" hostname [ ":" port ]
An example upload-pack request in packet line format is:
0032git-upload-pack /git-bottom-up\0host=localhost\0
Here localhost is the target host and /git-bottom-up the repository path on the target system. Note that by requesting the upload-pack to be used on the remote end we initiate a clone/fetch/ls-remote request used to transfer data from the server to the client.
The following example defines a function that will construct the initial request command:
gitProtoRequest :: String -> String -> String
gitProtoRequest host repo = pktLine $ "git-upload-pack /" ++ repo ++ "\0host="++host++"\0"
This allows us to create a minimal client that implements ls-remote as follows:
data Remote = Remote {
getHost :: String
, getPort :: Maybe Int
, getRepository :: String
} deriving (Eq, Show)
lsRemote' :: Remote -> IO [PacketLine]
lsRemote' Remote{..} = withSocketsDo $
withConnection getHost (show $ fromMaybe 9418 getPort) $ \sock -> do
let payload = gitProtoRequest getHost getRepository
send sock payload
response <- receive sock
send sock flushPkt -- Tell the server to disconnect
return $ parsePacket $ L.fromChunks [response]
This
- creates a TCP connection to the given
Remote(extracted from the git URL), - sends a protocol request in packet line format,
- reads the response from the socket,
- sends a flush packet (
0000) to terminated the connection, - parses the response into a
PacketLinedata structure (this is mainly to easily extract the capabilities later on)
This uses the following fully functionining and complete git protocol TCP client:
{-# LANGUAGE OverloadedStrings, ScopedTypeVariables, BangPatterns #-}
-- | A git compatible TcpClient that understands the git packet line format.
module Git.Remote.TcpClient (
withConnection
, send
, receiveWithSideband
, receiveFully
, receive
) where
import qualified Data.ByteString.Char8 as C
import qualified Data.ByteString as B
import Network.Socket hiding (recv, send)
import Network.Socket.ByteString (recv, sendAll)
import Data.Monoid (mempty, mappend)
import Numeric (readHex)
withConnection :: HostName -> ServiceName -> (Socket -> IO b) -> IO b
withConnection host port consumer = do
sock <- openConnection host port
r <- consumer sock
sClose sock
return r
send :: Socket -> String -> IO ()
send sock msg = sendAll sock $ C.pack msg
-- | Read packet lines.
receive :: Socket -> IO C.ByteString
receive sock = receive' sock mempty
where receive' s acc = do
maybeLine <- readPacketLine s
maybe (return acc) (receive' s . mappend acc) maybeLine
-- =================================================================================
openConnection :: HostName -> ServiceName -> IO Socket
openConnection host port = do
addrinfos <- getAddrInfo Nothing (Just host) (Just port)
let serveraddr = head addrinfos
sock <- socket (addrFamily serveraddr) Stream defaultProtocol
connect sock (addrAddress serveraddr)
return sock
-- | Read a git packet line (variable length binary string prefixed with the overall length).
-- Length is 4 byte, hexadecimal, padded with 0.
readPacketLine :: Socket -> IO (Maybe C.ByteString)
readPacketLine sock = do
len <- readFully mempty 4
if C.null len then return Nothing else -- check for a zero length return -> server disconnected
case readHex $ C.unpack len of
((l,_):_) | l > 4 -> do
line <- readFully mempty (l-4)
return $ Just line
_ -> return Nothing
where readFully acc expected = do
line <- recv sock expected
let len = C.length line
acc' = acc `mappend` line
cont = len /= expected && not (C.null line)
if cont then readFully acc' (expected - len) else return acc'
Apart from the usual ceremony to set up and connect the socket, the readPacketLine function contains the git specific part of the TcpClient.
The first step is to read 4 bytes from the socket to determine how many bytes to read to fully consume a packet line. readFully is a recursive function that is used to ensure to read the requested number of bytes from the socket as the contract for recv does not guarantee that the requested number of bytes can be read at once.
Depending on the length of the packet line we consume the rest of the packet line or return Nothing. If the length signals that we received an empty packet (i.e. 0004 or a flush packet 0000) we stop reading and return Nothing (note: for readers unfamiliar with Haskell, Haskell’s return is quite different to the return used in imperative languages where it terminates the execution, in Haskell it is used to wrap a pure value in a container, here the IO monad).
After the server returns the ref advertisement the client can terminate the connection by sending a flush packet (0000 - e.g. if the client is already up to date) or enter the negotiation phase the determines the optimal pack file to send from the server to the client.
Implementing pack file negotiation
Now that the client has knowledge about all the refs the server advertised it can now request the refs it needs from the server. The clone use case is the simplest use case as a full clone simply requests all the refs the server has.
Thus the general flow is:
Client -> Initate proto request
Ref advertisement <- Server
Client -> Negotiation request (list of refs the client wants)
Send packfile <- Server
The (for the clone case) simplified ABNF for a protocol request looks like this:
upload-request = want-list
flush-pkt
want-list = first-want
*additional-want
first-want = PKT-LINE("want" SP obj-id SP capability-list LF)
additional-want = PKT-LINE("want" SP obj-id LF)
The client list all the commit ids it wants, prefixed by want using the packet line format. It adds the capabilities it wants to be in effect on the first want line:
T(6) 127.0.0.1:55494 -> 127.0.0.1:9418 [AP]
0077want 8c25759f3c2b14e9eab301079c8b505b59b3e1ef multi_ack_detailed side-band-64k thin-pack ofs-delta agent=git/1.8.2
0032want 8c25759f3c2b14e9eab301079c8b505b59b3e1ef
0032want 4574b4c7bb073b6b661abd0558a639f7a32b3f8f
The protocol contract requirest that at least one want command must be send and that the client cannot request a commit-id that wasn’t advertised by the server.
Based on the refs the client wants, the server will generate a pack file that will contain all the required refs and the objects that are reachable from those refs. The server then send pack the packfile which will be stored by the client into a temporary location to then create a local git repository.
This flow can be easily observed in the two following functions the client uses to implement the clone operation. The receivePack implements the packfile negotiation and returns both the actual raw pack file (as a strict ByteString) and the list of refs that the server advertised. That list will later on be used to recreate the refs in the local repository.
receivePack :: Remote -> IO ([Ref], B.ByteString)
receivePack Remote{..} = withSocketsDo $
withConnection getHost (show $ fromMaybe 9418 getPort) $ \sock -> do
let payload = gitProtoRequest getHost getRepository
send sock payload
response <- receive sock
let pack = parsePacket $ L.fromChunks [response]
request = createNegotiationRequest ["multi_ack_detailed",
"side-band-64k",
"agent=git/1.8.1"] pack ++ flushPkt ++ pktLine "done\n"
send sock request
!rawPack <- receiveWithSideband sock (printSideband . C.unpack)
return (mapMaybe toRef pack, rawPack)
where printSideband str = do
hPutStr stderr str
hFlush stderr
The createNegotiationRequest function creates the want lines the client sends back to the server, amending the first line with the capabilities that should be in effect. We need to filter the refs the server advertised. If the remote repository has any annotated tag objects, the ref advertisement will contain both the object id for the tag object and the object id for the commit the tag points to. This is called a peeled ref. If there is a peeled ref it immediately follows the tag object ref and has a ^{} suffix. E.g.:
1eeeb26fb00aec91b6927cadf2f3f8d0ecacd5a1 refs/tags/v3.2.9.rc3
db1d5f40714a47c58c13ff7d9643e8a0dec6bef8 refs/tags/v3.2.9.rc3^{}
We filter both the peeled refs and only include refs that are in the refs/heads and refs/tags namespace:
-- PKT-LINE("want" SP obj-id SP capability-list LF)
-- PKT-LINE("want" SP obj-id LF)
createNegotiationRequest :: [String] -> [PacketLine] -> String
createNegotiationRequest capabilities = concatMap (++ "") . nub . map (pktLine . (++ "\n")) . foldl' (\acc e -> if null acc then first acc e else additional acc e) [] . wants . filter filterPeeledTags . filter filterRefs
where wants = mapMaybe toObjId
first acc obj = acc ++ ["want " ++ obj ++ " " ++ unwords capabilities]
additional acc obj = acc ++ ["want " ++ obj]
filterPeeledTags = not . isSuffixOf "^{}" . C.unpack . ref
filterRefs line = let r = C.unpack $ ref line
predicates = map ($ r) [isPrefixOf "refs/tags/", isPrefixOf "refs/heads/"]
in or predicates
One capability we want to have in effect is the side-band capability. This instructs the server to send multiplexed progress reports and error info interleaved with the packfile itself (see Documentation/technical/protocol-capabilities.txt). The side-band and side-band-64k capabilites are mutually exclusive and only differ in the size of the payload packets git will use (1000 bytes vs 65520 bytes in the case of side-band-64k).
The receiveWithSideband function knows how to demultiplex the pack file response:
receiveWithSideband :: Socket -> (B.ByteString -> IO a) -> IO B.ByteString
receiveWithSideband sock f = recrec mempty
where recrec acc = do
!maybeLine <- readPacketLine sock
let skip = recrec acc
case maybeLine of
Just "NAK\n" -> skip -- ignore here...
Just line -> case B.uncons line of
Just (1, rest) -> recrec (acc `mappend` rest)
Just (2, rest) -> f ("remote: " `C.append` rest) >> skip -- FIXME - scan for linebreaks and prepend "remote: " accordingly (see sideband.c)
Just (_, rest) -> fail $ C.unpack rest
Nothing -> skip
Nothing -> return acc
It reads the first byte that comes after the packet line length. The sideband channel indicators are:
1the remainder of the packet line is a chunk of the pack file - this is the payload channel2this is progress information that the server sends - the client prints that on STDERR prefixed withremote: "3this is error infomration that will cause the client to print out the message on STDERR and exit with an error code (not implemented in our example)
This the clone'function:
clone' :: GitRepository -> Remote -> IO ()
clone' repo remote@Remote{..} = do
(refs,packFile) <- receivePack remote
let dir = pathForPack repo
-- E.g. in native git this is something like .git/objects/pack/tmp_pack_6bo2La
tmpPack = dir </> "tmp_pack_incoming"
_ <- createDirectoryIfMissing True dir
B.writeFile tmpPack packFile
_ <- runReaderT (createGitRepositoryFromPackfile tmpPack refs) repo
removeFile tmpPack
runReaderT checkoutHead repo
- Receives the pack file and the list of advertised refs
- Writes the pack file to a known temporary location
- Parses the pack file and then
- Checks out the
HEADin the working directory
To understand and implement the last two steps we next have a closer look at the pack file format.
Pack file format
The pack file is used to efficiently transfer or store a number of git objects. When used as a storage optimization the *.pack file is accompanied by an index file that allows efficient lookup of objects in the pack file. When used as a transfer mechanism the pack file will be transfered as is and the index created locally.
The pack format is described in Documentation/technical/pack-format.txt in the git source.
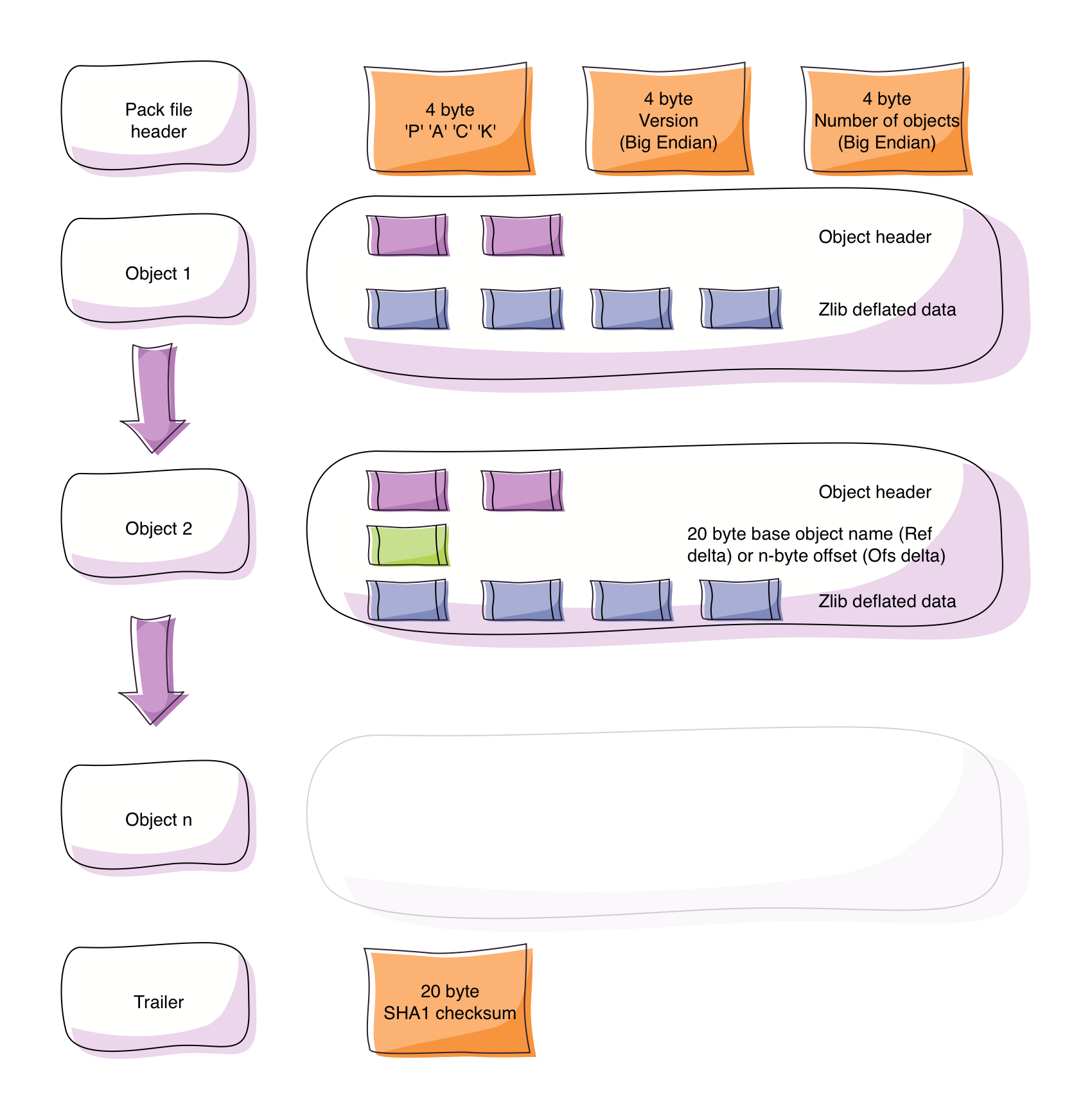
The packfile consists of:
- A 12 byte pack file header with:
- a 4-byte magic byte with the value
'P' 'A' 'C' 'K'(decimal1346454347) - a 4 byte pack file version
- a 4 byte number of objects in the packfile
- a 4-byte magic byte with the value
nobjects with- a variable length object header that contains the type of object (see below) and the length of the inflated/uncompressed data that follows
- only for deltified objects: the 20 byte base object name (for objects of type
OBJ_REF_DELTA) or a relative (negative) offset from the delta object’s position in the pack for objects of typeOBJ_OFS_DELTA- see below). - zlib deflated/compressed object data
- A 20 byte SHA1 checksum of all of the above as trailer
The objects in the pack file are commit, tag, tree and blob objects. A deltified object has a pointer to a base object and as its payload the delta between the base version and the subsequent version of that object. See below for a discussion of the delta encoding git uses.
Before we further investigate the pack file format it’s worth pointing out a few tools and commands that can be used to get a better understanding about how objects are represented in the pack file.
The git verify-pack command can be used to validate pack files. This only works for *.pack files though that have an accompanying index file.
[4888] λ > git verify-pack -v .git/objects/pack/pack-85376214c718d1638a7aa83af4d20302d3fd8efc.pack
2486a54b0fa69143639407f94082cab866a91e08 commit 228 153 12
e8aa4319f3fe937cfb498bf944fa9165078d8245 commit 179 122 165
0376e0620690b259bfc8e381656c07217e4f0b8c tree 317 299 287
d06be33046be894124d2c1d86af7230f17773b3f blob 74 72 586
812387998220a52e6b50cce4a11abc65bbc1ec97 blob 22 29 658
60596d939fad1364fa0b179828b4406761463b8d blob 1466 778 687
42d5f4d92691c3b90b2b66ecb79dfb60773fa1a1 blob 1109 452 1465
99618348415a3a0f78222e54c03c51e638fbad41 blob 466 340 1917 1 42d5f4d92691c3b90b2b66ecb79dfb60773fa1a1
An entry for a non deltified object has the following format:
SHA1 type size size-in-pack-file offset-in-packfile
Entries for deltified objects use:
SHA1 type size size-in-packfile offset-in-packfile depth base-SHA1
This comes in handy when implementing the code that reads and recreates the objects stored in the pack file.
Another built-in command is git unpack-objects, a command that creates loose object files from a pack file and doesn’t require an index file to be present. It therefore can be used on the packfile received from a remote repository for which there is no index file yet. This command needs to be executed in an existing git repository and the objects contained in the pack file will be unpacked into the .git/objects directory of that repository:
git unpack-objects --strict < test-pack.pack
Any suitable hexeditor (e.g. xxd, od or HexFiend, a GUI application on the Mac) is useful when it comes to reading and comparing the pack file data.
Note: As part of the git clone process, the pack file needs to be read and understood to validate the objects that come in by comparing the checksums and to generate an index file for the pack that is stored in the local repository. For this clone implementation I’m unpacking the pack file into loose objects (one file per object) instead to simplify the streaming pack file handling - this is merely a shortcut though as it unnecessarily creates a large number of object files which makes cloning of large repositories slower than it needs to be.
Pack file header
Reading the pack file header is trivial. The parsePackFile function reads the first 12 bytes in 4 byte groups (using big endian with the Most Significant Byte first). It compares the magic byte to ensure we are reading a git pack file and then continues reading the number of objects the pack file header defines:
parsePackFile :: I.Iteratee ByteString IO Packfile
parsePackFile = do
magic <- endianRead4 MSB -- 4 bytes, big-endian
version' <- endianRead4 MSB
numObjects' <- endianRead4 MSB
if packMagic == magic
then parseObjects version' numObjects'
else return InvalidPackfile
where packMagic = fromOctets $ map (fromIntegral . ord) "PACK"
Pack file objects
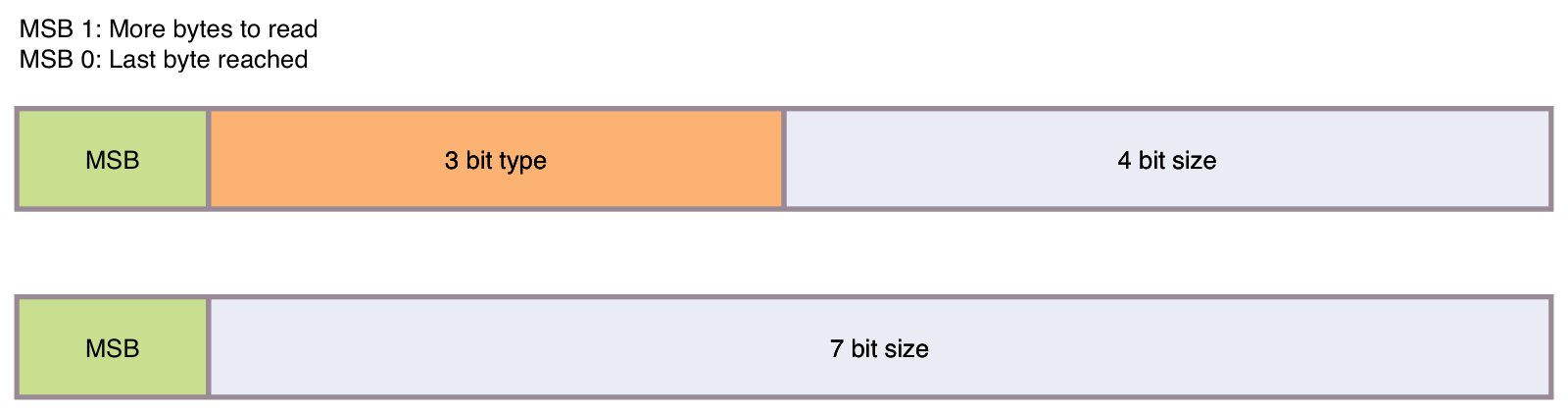
The pack file object header uses a variant of a variable length unsigned integer encoding that contains the object type in the first byte.
That first byte consists of:
- The most significant bit (MSB) that determines whether we need to read more bytes to get the encoded object size (if the MSB is set we read the next byte)
- 3 bits with the object type (from
cache.h):OBJ_COMMIT= 1OBJ_TREE= 2OBJ_BLOB= 3OBJ_TAG= 4OBJ_OFS_DELTA= 6OBJ_REF_DELTA= 7
- 4 bits with the size (partial size if the MSB is set and more bytes need to be read)
The following bytes after the first byte contain parts of the overall length in the least significant 7 bits of the octet while the MSB is again used to indicate whether more bytes need to be read.
The following diagram shows an example consisting of two octets:
Reading the object header is straightforward, we read one byte, extract the object type, initial size information from the lower nibble and whether to continue reading size information by looking at the MSB:
byte <- I.head -- read 1 byte
let objectType = byte `shiftR` 4 .&. 7 -- shift right and bitwise AND
-- to mask the bit that was the MSB before shifting
initialSize = fromIntegral $ byte .&. 15 -- mask type and MSB
-- recursivley read the following bytes if the MSB is set
size <- if isMsbSet byte then parseObjectSize initialSize 0 else return initialSize
To check whether the most significant bit is set we define the isMsbSet function that we will use in other places:
isMsbSet x = (x .&. 0x80) /= 0 -- 0x80 = 128 decimal
The following bytes are even simpler to read as we only care about the 7 least significant bits:
parseObjectSize size' iter = do
nextByte <- I.head
let add = (coerce (nextByte .&. 127) :: Int) `shiftL` (4 + (iter * 7)) -- shift depends on the number of iterations
acc = size' + fromIntegral add
if isMsbSet nextByte then
parseObjectSize acc (iter + 1)
else
return acc
where coerce = toEnum . fromEnum
The overall length is then:
size0 + size1 + … + sizeN
after shifting each part 0, 4 + (n-1) * 7 to the left. size0 is the least, sizeN the most significant part.
After reading the last byte of the object header we have the size of the inflated/uncompressed object and its type.
While Haskell is usually very concise, the C implementation admittedly achieves the same with a lot less fanfare:
type = (c >> 4) & 7;
size = (c & 15);
shift = 4;
while (c & 0x80) {
pack = fill(1);
c = *pack;
use(1);
size += (c & 0x7f) << shift;
shift += 7;
}
Back to our Haskell implementation, here is the full definition of the function to read a single pack file object is (see src/Git/Pack/Packfile.hs):
parsePackObject :: I.Iteratee ByteString IO (Maybe PackfileObject)
parsePackObject = do
byte <- I.head -- read 1 byte
let objectType' = byte `shiftR` 4 .&. 7 -- shift right and masking the 4th least significtan bit
initial = fromIntegral $ byte .&. 15
size' <- if isMsbSet byte then parseObjectSize initial 0 else return initial
obj <- toPackObjectType objectType'
!content <- I.joinI $ enumInflate Zlib defaultDecompressParams I.stream2stream
return $ (\t -> PackfileObject t size' content) <$> obj
-- Map the internal representation of the object type to the PackObjectType
toPackObjectType :: (Show a, Integral a) => a -> I.Iteratee ByteString IO (Maybe PackObjectType)
toPackObjectType 1 = return $ Just OBJ_COMMIT
toPackObjectType 2 = return $ Just OBJ_TREE
toPackObjectType 3 = return $ Just OBJ_BLOB
toPackObjectType 4 = return $ Just OBJ_TAG
toPackObjectType 6 = do
offset <- readOffset 0 0
return $ Just (OBJ_OFS_DELTA offset)
toPackObjectType 7 = do
baseObj <- replicateM 20 I.head -- 20-byte base object name SHA1
return $ Just (OBJ_REF_DELTA baseObj)
toPackObjectType _ = return Nothing
Based on the type we
- inflate/decompress the following bytes when the object is either a
commit,tag,treeorblob - read the base object id or the offset if this is a deltified object (i.e. when the object type is either
6or7) and then the compressed delta data
An interesting challenge is the fact that the pack file object header contains the size of the uncompressed object, but not the size of the compressed object. In order to read the objects the only way to identify object boundaries (i.e. where in the pack file the next object starts) is to actually inflate the zlib compressed data and thus consuming the following bytes that are part of the zlib compressed content. While the zlib API in C (i.e. inflate()) indicates whether it has reached the end of the compressed data and has produced all of the uncompressed output (see http://www.zlib.net/zlib_how.html), I found only the Iteratee based implementation (iteratee-compress) to be suitable for achieving the same in Haskell. The following excerpt from the parsePackObject function inflates the zlib compressed data from the pack file stream and creates a PackfileObject with the object type information, the size information from the pack and the inflated data:
!content <- I.joinI $ enumInflate Zlib defaultDecompressParams I.stream2stream
return $ (\t -> PackfileObject t size' content) <$> obj
This allows the Git.Pack.Packfile module to fully read the pack file and to create an internal pack file representation that contains a list of PackfileObjects with fully inflated content.
Before this pack file can be written to disk we need to handle the deltified objects though as our internal representation contains a mix of deltified and undeltified (i.e. complete) objects.
Delta encoding
The deltified representations (pack file object types 6 & 7) in the packfile use delta compression to minimize the amount of data that needs to be transferred and/or stored. Deltification only happens in pack files.
The following (from “File System Support for Delta Compression”) gives a good general definition of delta compression:
Delta compression consists of representing a target version’s contents as the mutation (delta) of some existing source contents to achieve the same goal, a reduction in space or time. Typically, the target and source are related file versions and have similar contents.
Thus delta encoding allows file versions to be recreated based on an original source file and one or more delta files. Subsequent delta files can be applied to the patched result of the previous delta file and its source (called the “delta chain” in git - the git verify-pack command will print a histogram of the delta chain length when invoked with the --verbose flag). An important attribute of the delta encoding is the fact that it can be used for both binary and text files.
The delta compression algorithm that is used in git was originally based on xdelta and LibXDiff but was further simplified for the git use case (see the “diff’ing files” thread on the git mailinglist). The following discussion is based on the delta file format used by git and the patch-delta.c and diff-delta.c files from the git source.
Format of the delta representation
The git delta encoding algorithm is a copy/insert based algorithm (this is apparent in patch-delta.c). The delta representation contains a delta header and a series of opcodes for either copy or insert instructions.
From “File System Support for Delta Compression”:
The copy/insert class of delta algorithms use a string matching technique to locate matching offsets in the source and target versions and then emit a sequence of copy instructions for each matching range and insert instructions to cover the unmatched regions
The copy instructions contain an offset into the source buffer and the number of bytes to copy from the source to the target buffer starting from that offset.
The insert opcode itself is the number of bytes to copy from the delta buffer into the target. This will contain the bytes that have been added and are not part of the source buffer at this point.
The delta buffer starts with a header that contains the length of the source and target buffers to be able to verify the restored/patched result. Lengths are again encoded as a variable length integer where the MSB indicates whether another var length octet follows.
Delta buffer layout:
| Varint - Lengt of the source/base buffer |
| Varint - Length of the target buffer |
| n copy/insert instructions |
Testing
In order to test the delta encoding implementation the git source allows us to build a test-delta binary that can be used to generate delta data and to restore a target file from a source and delta representation.
$> cd ~/dev/git/git-source
$> make configure
$> ./configure
$> make test-delta
This will generate a test-delta binary with a delta and patch mode:
[4926] λ > ./test-delta
usage: test-delta (-d|-p) <from_file> <data_file> <out_file>
Generate a delta file:
./test-delta -d test-delta.c test-delta-new.c out.delta
Restore the original file based on the delta:
./test-delta -p test-delta.c out.delta restored-test-delta-new.c
Verify that both are in fact the same:
diff -q restored-test-delta-new.c test-delta-new.c
This workflow can then be used to generate arbitrary delta files and to test our own implementation.
Patch algorithm example
An example can help getting a better intuiton for how the delta encoding works.
In a source file (the zlib.c file from the git source) a function definition was moved down inside the same file and a new comment added.
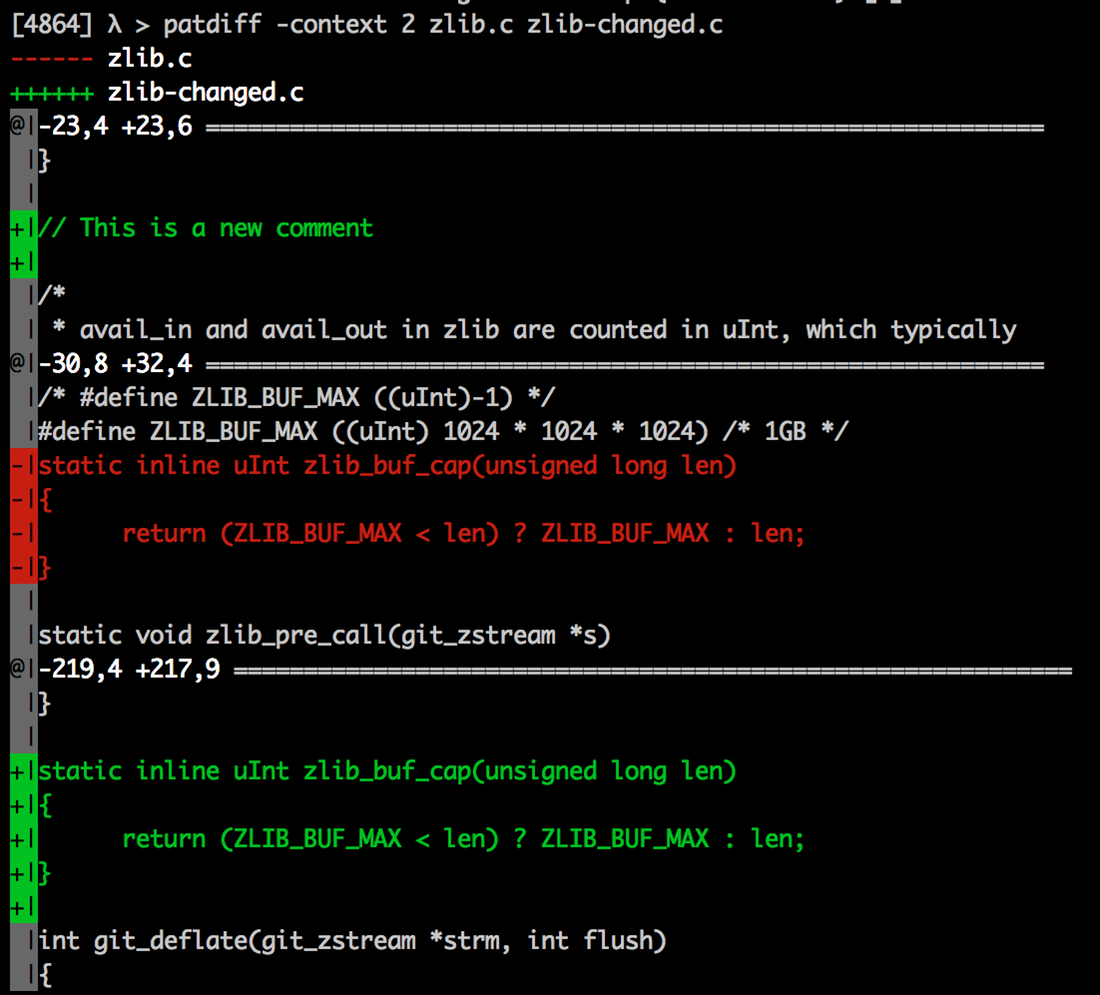
Using test-delta we can generate a delta file using the old and new version of this file:
./test-delta -d zlib.c zlib-changed.c zlib-delta
This is the resulting delta file:
[4950] λ > xxd -b zlib-delta
0000000: 10010001 00101110 10101100 00101110 10110000 11010001 ......
0000006: 00000001 00010111 00101111 00100000 01010100 01101000 ../ Th
000000c: 01101001 01110011 00100000 01101001 01110011 00100000 is is
0000012: 01100001 00100000 01101110 01100101 01110111 00100000 a new
0000018: 01100011 01101111 01101101 01101101 01100101 01101110 commen
000001e: 01110100 10110011 11001110 00000001 00100111 00000001 t...'.
0000024: 10110011 01011111 00000011 01101100 00010000 10010011 ._.l..
000002a: 11110101 00000010 01101011 10110011 11001011 00010011 ..k...
0000030: 01000110 00000011
The first step is to read the source and target lengths. The fact that the MSB of the first byte is set indicates that we need to read the next byte to get the size information so the first two bytes make up the length of the source buffer:
10010001 00101110
Reading the variable length integer simply boils down to:
1. Mask the MSB 10010001 & 127 -> 00010001 = 17
2. Left shift the 2nd byte 00101110 << 7 = 5888
by (iteration * 7). As this is the first additional byte this is (1 * 7)
3. Bitwise OR 1st and 2nd byte 17 | 5888 = 5905
which is the same approach we saw when reading the object header in the pack file. We can check that the length we read is in fact correct:
[4868] λ > wc -c zlib.c
5905 zlib.c
The next two bytes are the length of the target buffer (which is 5932 bytes).
The significant part of the implentation for this is:
where decodeSize offset = do
skip offset
byte <- getWord8
next (maskMsb byte) 7 byte $ succ offset
next base shift byte' count | isMsbSet byte' = do
b <- getWord8
let len = base .|. ((maskMsb b) `shiftL` shift)
next len (shift + 7) b $ succ count
next finalLen _ _ count = return (finalLen, count)
maskMsb byte = fromIntegral $ byte .&. 0x7f
where decodeSize will be called with the offset of the length information for the source (0 in this case) and target sizes (number of bytes required to represent the source size).
After reading the header information the remainig btyes are either copy or insert instructions.
The next byte (10110000) is a copy instruction based on the fact that the MSB is set.
The offset into the source buffer and the number of bytes to copy can then be extracted as follows.
Start at the LSB:
10110000 & 0x01 - 1st bit not set
10110000 & 0x02 - 2nd bit not set
10110000 & 0x04 - 3rd bit not set
10110000 & 0x08 - 4th bit not set
None of the offset bits are set, we don’t read any offset value so the offset is 0. This means we copy from the start of the source buffer.
10110000 & 0x10 - 5th bit is set. We read the next byte (11010001)
10110000 & 0x20 - 6th bit is set. We read the next byte (00000001), left
shift it by 8 and OR it to the previously read value:
11010001 | (00000001 << 8) = 209 | 256 = 465
00000000 & 0x40 - 7th bit is not set.
465 is the number of bytes to copy from the source into the target buffer, starting at offset 0.
The next byte 00010111 (byte 8) is an insert instruction (MSB not set). The insert instruction is simply the number of bytes to copy from the delta into the target buffer.
Note: Conversion between different numeric representations is quickly done in the shell using:
$> echo $(( 16#A4 )) # convert hexadecimal into decimal
164
$> echo $(( 2#00010111 )) # convert binary into decimal
23
In this case we copy 23 bytes from the delta into the target. These are:
$> < zlib-delta tail -c +9 | head -c 23
/ This is a new comment
The full set of copy/insert instructions is:
- Copy 465 bytes from the source into the target, starting at offset 0
- Insert 23 bytes from the delta buffer into the target
- Copy 295 bytes, starting at offset 462
- Copy 4204 bytes, starting at offset 863
- Copy 107 bytes, starting at offset 757
- Copy 838 bytes, starting at offset 5067
This can easily be verified manually:
head -c 465 zlib.c >> manual-target-zlib.c
< zlib-delta tail -c +9 | head -c 23 >> manual-target-zlib.c
< zlib.c tail -c +463 | head -c 295 >> manual-target-zlib.c
< zlib.c tail -c +864 | head -c 4204 >> manual-target-zlib.c
< zlib.c tail -c +758 | head -c 107 >> manual-target-zlib.c
< zlib.c tail -c +5068 | head -c 838 >> manual-target-zlib.c
Which yields the same restored file:
[4905] λ > diff manual-target-zlib.c zlib-changed.c && echo $?
0
Looking at the sizes of our test files in bytes, we can see that by using delta encoding the space requirements for files that are similar can be significantly reduced:
[4908] λ > wc -c zlib-delta zlib.c zlib-changed.c
50 zlib-delta
5905 zlib.c
5932 zlib-changed.c
This is 5905 for the base version + 50 bytes for the delta compared to storing both versions independently ()5905 + 5932).
Git further reduces the space requirements by storing the base and delta objects zlib compressed in the packfile.
Implementation of the delta encoding algorithm
For the clone implementation we only need to deal with the much simpler to implement patch operation that recreates the target content based on the source and the delta. This is fortunately much easier than the task of creating a suitable delta file based on the source and target files (see 2 for further discussion on this).
The main function our Git.Pack.Delta module exposes is the patch function that accepts a source and a delta bytestring (bytestrings are Haskell’s version of byte vectors/arrays) and returns the re-created target bytestring.
patch :: B.ByteString -- ^ Source/Base
-> B.ByteString -- ^ Delta
-> Either String B.ByteString
patch base delta = do
header <- decodeDeltaHeader delta
if B.length base == sourceLength header then
fst $ runGet (run (getOffset header) base delta) delta
else Left "Source length check failed"
Skipping the parsing of the header that was mentioned above the main building blocks are:
-- | Parse the delta file and transform the source into the target ByteString
run :: Int -> B.ByteString -> B.ByteString -> Get B.ByteString
run offset source delta = do
skip offset
cmd <- getWord8
runCommand cmd B.empty source de
We skip the header based on the offset from the start of the delta to the delta payload. We read the first byte which is the opcode and execute either a copy or insert instruction using the runCommand function:
-- | Execute the @copy/insert@ instructions defined in the delta buffer to
-- restore the target buffer
runCommand :: Word8 -> B.ByteString -> B.ByteString -> t -> Get B.ByteString
runCommand cmd acc source delta = do
result <- choose cmd
finished <- isEmpty
let acc' = B.append acc result
if finished then return acc'
else do
cmd' <- getWord8
runCommand cmd' acc' source delta
where choose opcode | isMsbSet opcode = copyCommand opcode source
choose opcode = insertCommand opcode
If the most significant byte is set this is a copy, otherwise it is an insert instruction. If it is an insert command the command itself is the number of bytes to copy from the delta into the target buffer so we simply apply the insertCommand function.
-- | Read @n@ bytes from the delta and insert them into the target buffer
insertCommand :: Integral a => a -> Get B.ByteString
insertCommand = getByteString . fromIntegral
The copy instruction is slightly more involved and caters for larger offset (offset in the source) and size (number of bytes to copy) lengths (which is resolved using the readCopyInstruction function):
-- | Copy from the source into the target buffer
copyCommand :: Word8 -> B.ByteString -> Get B.ByteString
copyCommand opcode source = do
(offset, len) <- readCopyInstruction opcode
return $ copy len offset source
where copy len' offset' = B.take len' . B.drop offset'
readCopyInstruction :: (Integral a) => Word8 -> Get (a, a)
readCopyInstruction opcode = do
-- off -> offset in the source buffer where the copy will start
-- this will read the correct subsequent bytes and shift them based on
-- the set bit
offset <- foldM readIfBitSet 0 $ zip [0x01, 0x02, 0x04, 0x08] [0,8..]
-- bytes to copy
len' <- foldM readIfBitSet 0 $ zip [0x10, 0x20, 0x40] [0,8..]
let len = if coerce len' == 0 then 0x10000 else len'
-- FIXME add guard condition from `patch-delta.c`: if (unsigned_add_overflows(cp_off, cp_size) || ...
return $ (coerce offset, coerce len)
where calculateVal off shift = if shift /= 0 then (\x -> off .|. (x `shiftL` shift)::Int) . fromIntegral else fromIntegral
readIfBitSet off (test, shift) = if opcode .&. test /= 0 then liftM (calculateVal off shift) getWord8 else return off
coerce = toEnum . fromEnum
To test the delta implementation we can use the following simple main function and a delta file produced by the test-delta command from the git source:
main :: IO ()
main = do
(sourceFile:deltaFile:_) <- getArgs
source <- B.readFile sourceFile
delta <- B.readFile deltaFile
header <- decodeDeltaHeader delta
print header
print $ B.length source
either putStrLn (B.writeFile "target.file") $ patch source delta
Using the original source and the delta this will create a patched target.file:
$> runhaskell -isrc src/Git/Pack/Delta.hs zlib.c zlib-delta
DeltaHeader {sourceLength = 5905, targetLength = 5932, getOffset = 4}
5905
With at working patch function we can now recreate the actual content based on the deltified and the base objects that are contained in the pack file.
Ref vs. Ofs delta
The pack file format defines two different types of deltified objects: OBJ_OFS_DELTA and OBJ_REF_DELTA. They differ only in the way the base (or source) object is identified in the pack file. OBJ_REF_DELTA uses the 20-byte SHA1 that identifies the object, whereas OBJ_OFS_DELTA uses the negative offset from the delta object header in the pack file (as mentioned above in the pack file section). When delta encoding was originally added, git started with the ref based delta, the OBJ_OFS_DELTA object type was later introduced in #eb32d236 mainly to reduce the size of the pack file. Whether the client supports offset based deltas in the pack file can be signaled during the pack file negotiation by setting the ofs-delta capability (if the server indicates that this is supported).
From Documentation/technical/protocol-capabilities.txt:
ofs-delta Server can send, and client understand PACKv2 with delta referring to its base by position in pack rather than by an obj-id. That is, they can send/read OBJ_OFS_DELTA (aka type 6) in a packfile.
As a simplification for our clone implementation we don’t use this capability in the request and therefore only need to implement the lookup of ref based base objects.
Summary
We now have
- a means to read the pack file into a list of
PackObjects that contain the inflated objects - a
patchfunction to recreate objects based on a base object and the delta content.
We can therefore fully recreate the objects given the pack file we received.
Git repository
To create a valid git repository we need to create a directory layout and a set of files that git requires to recognize this directory as a valid git repository. Conceptually the files and directories can be roughly split into the object store, refs and the index areas.
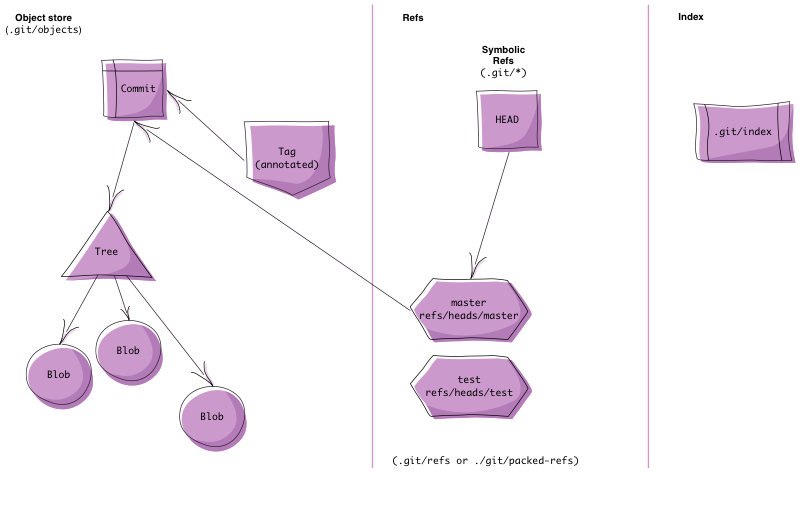
The Git Repository Layout man page has detailed information about the contents of the git directory.
Object store
To correctly populate the git object store we need to understand the object types git supports, how it represents those objects and how they are stored on disk.
Git has two different represantations for objects. The “loose object” format stores every object in a separate file in the .git/objects/ directory. Git regularly packs the loose objects into the pack file we discussed above, leveraging delta compression to reduce the space requirements of similar files. The loose objects are stored using the SHA1 hash as the filename, where the first two alphanumeric characters are used as a directory name under .git/objects/ (this results in a simple16*16 partition of the objects directory) and the remaining 38 characters as the actual filename.
The following example shows both loose objects and a pack file with its accompanying index file:
[4866] λ > tree .git/objects/
.git/objects/
├── 08
│ └── 24d8f1ed19e4e07cf03e40aeebe07b95a68f7d
├── 61
│ └── 3956b77de7b48bdd82375716c1f1b78fd30764
├── d4
│ └── d697777ba37a1588269b2639fb93d14af8e781
├── fc
│ └── f5367cdfdc59e08428afa5a0d62893bcca0cf0
├── info
│ └── packs
└── pack
├── pack-5faf642231915b153fd273701866c5526c680bc6.idx
└── pack-5faf642231915b153fd273701866c5526c680bc6.pack
The object store can be queried using git cat-file:
[4869] λ > git cat-file -t fcf5367cdfdc59e08428afa5a0d62893bcca0cf0
tree
[4870] λ > git cat-file -p fcf5367cdfdc59e08428afa5a0d62893bcca0cf0
100644 blob 613956b77de7b48bdd82375716c1f1b78fd30764 README.md
040000 tree e9378f166d4ddbf93a4bc1c91af2d9f3ea34ebdd _src
040000 tree 2dba9669371668a7030d79e66521742660df9818 images
Objects on disk
The 4 object types git deals for the usual operations are:
- The
commitstores the commit message, dates and authore/commited information and points to a single tree object. A commit can have zero (for the root commit(s)), one or more parent commit ids. The commit pointer to the parent(s) forms the commit graph. - A
blobstores the actual file content without any meta information (e.g. the file name). - A
treecontains path names and permissions with pointers to blob or tree objects - it represents the directories and filenames of the tracked content. - A
tagan annotated tag stores the tag message, date and the identiy of the person creating the tag. Git also uses so called light-weight tags that are simply pointers in the ref hierarchy without having any additionaly tag meta information.
See http://git-scm.com/book/en/Git-Internals-Git-Objects for further detailed information.
As already mentioned, git stores a single pack file and generates an accompanying index file without creating any loose objects during the initial clone. Instead of using the same approach (and because we already read the pack file) we simply unpack the objects and store them as loose objects. This is obviously a less efficient approach and makes our clone operation much slower than it needs to be.
As our internal packfile representation already contains the decompressed objects, we simply need to store them correctly (recreating the deltified objects) without providing functionality to create each object type from scratch.
Object storage format
The object content stored on disk uses the following format:
From http://git-scm.com/book/en/Git-Internals-Git-Objects
Git constructs a header that starts with the type of the object, in this case a blob. Then, it adds a space followed by the size of the content and finally a null byte
Git concatenates the header and the original content and then calculates the SHA-1 checksum of that new content.
The encodeObject returns the correct disk representation of the object (file) content. Given the uncompressed content from the packfile as a bytestring it returns a pair that is the SHA1 hash and the on-disk content representation with the correct header:
-- header: "type size\0"
-- sha1 $ header ++ content
encodeObject :: ObjectType -> C.ByteString -> (ObjectId, C.ByteString)
encodeObject objectType content = do
let header = headerForBlob (C.pack $ show objectType)
blob = header `C.append` content
sha1 = hsh blob
(sha1, blob)
where headerForBlob objType = objType `C.append` " " `C.append` C.pack (show $ C.length content) `C.append` "\0"
hsh = toHex . SHA1.hash
Git stores the objects on disk using zlib compression. The writeObject function stores any object using our encoding function to create the object content:
writeObject :: GitRepository -> ObjectType -> C.ByteString -> IO FilePath
writeObject GitRepository{..} objectType content = do
let (sha1, blob) = encodeObject objectType content
(path, name) = pathForObject getName sha1
filename = path </> name
_ <- createDirectoryIfMissing True path
L.writeFile filename $ compress blob
return filename
where compress data' = Z.compress $ L.fromChunks [data']
-- Partition the namespace -> (2 chars,38 chars)
pathForObject :: String -> String -> (FilePath, String)
pathForObject repoName sha | length sha == 40 = (repoName </> ".git" </> "objects" </> pre, rest)
where pre = take 2 sha
rest = drop 2 sha
pathForObject _ _ = ("", "")
Using this functionwe can now unpack the pack file using the following function:
unpackPackfile :: Packfile -> WithRepository ()
unpackPackfile InvalidPackfile = error "Attempting to unpack an invalid packfile"
unpackPackfile (Packfile _ _ objs) = do
repo <- ask
unresolvedObjects <- writeObjects objs
liftIO $ forM_ unresolvedObjects $ writeDelta repo
where writeObjects (x@(PackfileObject (OBJ_REF_DELTA _) _ _):xs) = liftM (x:) (writeObjects xs)
writeObjects (PackfileObject objType _ content : xs) = do
repo <- ask
_ <- liftIO $ writeObject repo (tt objType) content
writeObjects xs
writeObjects [] = return []
tt OBJ_COMMIT = BCommit
tt OBJ_TREE = BTree
tt OBJ_BLOB = BBlob
tt OBJ_TAG = BTag
tt _ = error "Unexpected blob type"
writeDelta repo (PackfileObject ty@(OBJ_REF_DELTA _) _ content) = do
base <- case toObjectId ty of
Just sha -> liftIO $ readObject repo sha
_ -> return Nothing
if isJust base then
case patch (getBlobContent $ fromJust base) content of
Right target -> do
let base' = fromJust base
filename <- writeObject repo (objType base') target
return $ Just filename
Left _ -> return Nothing
else return Nothing -- FIXME - base object doesn't exist yet
writeDelta _repo _ = error "Don't expect a resolved object here"
unpackPackfile uses a 2-pass approach. It firstly writes out all the undeltified objects directly and accumulates a list of unresolved deltified objects. It then applies the writeDelta function to each of the deltified objects which looks up the base object that we just stored and recreates the undeltified object by applying the patch function using the base and delta content. The readObject function is the opposite of the writeObject and knows how to read the objects from the local repo.
This set of functions allows us to unpack all the objects (both deltified and undeltified) contained in the pack file into the local .git/objects object store.
Refs
With the objects in place git now needs an entry point into the commit graph. The branches and tags are those entry points and the tips of the branches and tags are known as refs, names that refer to the SHA1 based object ID for the object in the git repository. The refs are stored under the $GIT_DIR/refs directory (e.g. .git/refs/heads/master or in a packed format under .git/packed-refs). Refs contain the 40 hex digit SHA1 directly or a symbolic ref to another ref (e.g. ref: refs/heads/master). The special symbolic ref HEAD refers to the current branch.
An examplary ref structure in a git repository is:
.git/refs/
├── heads
│ └── master
├── remotes
│ └── origin
│ ├── HEAD
│ ├── master
│ └── pu
└── tags
├── 0.9
└── 1.0
The refs in the refs/heads directory are the local branches of the repository. The refs/tags directory contains both tags. In the case of an annotated tag the tag points to the tag object. For a lightweight tag, the tag file contains the object id of the tagged commit itself. The refs/remotes directory contains one sub directory for each remote that is configured (in this case the default origin). In the example the upstream repository has two branches master and pu and the symref HEAD that identifies the default branch of the upstream repositiory.
Listing the branches via git branch shows the same result:
$> git branch
* master
$> git branch --remotes
origin/HEAD
origin/master
origin/pu
Thus each ref name maps to a file with the same name in the given directory and its content is simply the SHA1 it refers to followed by a new line:
$> cat .git/refs/remotes/origin/master
8c25759f3c2b14e9eab301079c8b505b59b3e1ef
The canonical git implementation uses an optimization and stores refs in packed form in the $GIT_DIR/packed-refs file. The file is similar to the ref advertisement output and maps the refs to their object-ids within that single file:
$> cat .git/packed-refs
# pack-refs with: peeled
1865311797f9884ec438994d002b33f05e2f4844 refs/heads/delta-encoding-ffi
6bc699aad89341be9d07293815d0fa14f2e162ab refs/heads/fake-ref-creation
c666c23749af1e86169bed8ee0d1a2ac598e6ab0 refs/heads/master
496bf4f0724dd411855b374255b825f9b66cbfd0 refs/heads/sideband
Note: To simplify our implementation we ignore this optimisation and again store each ref in a separate file.
Implementation
In the createGitRepositoryFromPackfile function we call from our clone' function we can observe the basic steps required to create a working git repository:
createGitRepositoryFromPackfile :: FilePath -> [Ref] -> WithRepository ()
createGitRepositoryFromPackfile packFile refs = do
pack <- liftIO $ packRead packFile
unpackPackfile pack
createRefs refs
updateHead refs
We unpack the pack file and create objects in the .git/objects directory (it’s worth repeating - this is not how the native git client works - the native client creates an index file and use the pack file instead), then we create the refs and lastly the special symbolic ref HEAD.
The refs that need to be created are known from the inital ref advertisements and are simply mappings from the object ids (in this case commit ids) to the full ref name.
E.g.:
21ccebec0dd1d7e624ea2f22af6ac93686daf34f refs/heads/master
2c8b7bf47c81acd2a76c1f9c3be2a1f102b76d31 refs/heads/next
We use Ref data type to model this pair and we use this list of Refs from that initial ref advertisement to create the correct ref files:
data Ref = Ref {
getObjId :: C.ByteString
, getRefName :: C.ByteString
} deriving (Show, Eq)
createRefs :: [Ref] -> WithRepository ()
createRefs refs = do
let (tags, branches) = partition isTag $ filter (not . isPeeledTag) refs
writeRefs "refs/remotes/origin" branches
writeRefs "refs/tags" tags
where simpleRefName = head . reverse . C.split '/'
isPeeledTag = C.isSuffixOf "^{}" . getRefName
isTag = (\e -> (not . C.isSuffixOf "^{}" $ getRefName e) && (C.isPrefixOf "refs/tags" $ getRefName e))
writeRefs refSpace = mapM_ (\Ref{..} -> createRef (refSpace ++ "/" ++ (C.unpack . simpleRefName $ getRefName)) (C.unpack getObjId))
createRef :: String -> String -> WithRepository ()
createRef ref sha = do
repo <- ask
let (path, name) = splitFileName ref
dir = getGitDirectory repo </> path
_ <- liftIO $ createDirectoryIfMissing True dir
liftIO $ writeFile (dir </> name) (sha ++ "\n")
We again filter out the peeled tag refs and partition the refs into tags and branches that are stored in their respectives directories.
Note: Although origin is the default name for the remote repository a clone originates from, the native git clone command has the option --origin <name> to set the name of the remote to something other than origin when cloning. As our clone command currently doesn’t support any options we simply use the default origin remote name in our implementation.
After creating the refs the symbolic ref HEAD is created and it points to the same ref that is used by the upstream repository as the default branch (via its HEAD symref).
updateHead :: [Ref] -> WithRepository ()
updateHead [] = fail "Unexpected invalid packfile"
updateHead refs = do
let maybeHead = findHead refs
unless (isNothing maybeHead) $
let sha1 = C.unpack $ getObjId $ fromJust maybeHead
ref = maybe "refs/heads/master" (C.unpack . getRefName) $ findRef sha1 refs
in
do
createRef ref sha1
createSymRef "HEAD" ref
where isCommit ob = objectType ob == OBJ_COMMIT
findHead = find (\Ref{..} -> "HEAD" == getRefName)
findRef sha = find (\Ref{..} -> ("HEAD" /= getRefName && sha == (C.unpack getObjId)))
The updateHead function tries to resolve the commit-id of the upstream HEAD ref and then looks up the ref name that corresponds to that object-id in order to create the symref using the createSymRef function:
createSymRef :: String -> String -> WithRepository ()
createSymRef symName ref = do
repo <- ask
liftIO $ writeFile (getGitDirectory repo </> symName) $ "ref: " ++ ref ++ "\n"
The HEAD symref then looks similar to:
$> cat .git/HEAD
ref: refs/heads/master
At this point the local git repository is actually usable (e.g. commands like git log or git checkout work), albeit with an empty working copy.
Working copy and the index
With the object store populated and all the refs in place the next step is to “checkout” the files that match the repository snaphots HEAD points to.
In order to check out the current HEAD we need to:
- Read the
HEADsymref and resolve the commit it ultimately points to to use as the tip of our checked out working copy. - Given this commit we need to resolve the top level tree that our commit points to.
- Based on the tree we write out all the blobs that top level tree contains and recursively read the child tree entries to fully restore the directories and files in our working copy.
This requires us to be able to retrieve the objects from the object store and to then parse each object type and create an appropriate in-memory representation to enable tree traversal and ultimately the correct creation of files and directories.
Reading objects
Reading the objects is a two step process. The first step, the retrieval from the filesystem is already covered and is implemented by the readObject function:
readObject :: GitRepository -> ObjectId -> IO (Maybe Object)
readObject GitRepository{..} sha = do
let (path, name) = pathForObject getName sha
filename = path </> name
exists <- doesFileExist filename
if exists then do
bs <- C.readFile filename
return $ parseObject sha $ inflate bs
else return Nothing
where inflate blob = B.concat . L.toChunks . Z.decompress $ L.fromChunks [blob]
readObject looks up the correct file from the file system given its SHA1 and decompresses the content. As already mentioned above, the content is prefixed with a header that contains the object type and the overal size of the object seperated by a \NUL byte from the acutal object content:
object-type SP size \NUL object-content
The parseObject function parses the file content and creates an instance of an Object data type, extracting the object type and object content:
data Object = Object {
getBlobContent :: B.ByteString
, objType :: ObjectType
, sha :: ObjectId
} deriving (Eq, Show)
parseObject :: ObjectId -> C.ByteString -> Maybe Object
parseObject sha1 obj = eitherToMaybe $ parseOnly (objParser sha1) obj
-- header: "type size\0"
-- header ++ content
objParser :: ObjectId -> Parser Object
objParser sha1 = do
objType' <- string "commit" <|> string "tree" <|> string "blob" <|> string "tag"
char ' '
_size <- takeWhile isDigit
nul
content <- takeByteString
return $ Object content (obj objType') sha1
where obj "commit" = BCommit
obj "tree" = BTree
obj "tag" = BTag
obj "blob" = BBlob
obj _ = error "Invalid object type" -- The parser wouldn't get here anyway
This is still a close representation of the object content just with some meta information about the type and the object id. In order to use the git objects, e.g. resolve parent commits from a commit object or read the tree entries from a tree object, we need a 2nd level of object parsing that turns the generic (but tagged) Object into a more specifc object representation.
Commit
A commit object in git looks similar to this:
[4807] λ > git cat-file -p 3e879c7fd33cc3deecd99892033957dedc308e92
tree b11bff45acf0941c7ea5629dfff05760764423cd
parent c3a8276092194bd3ff80d7d6a4523c0f1c0e2df2
author Stefan Saasen <stefan@saasen.me> 1353116070 +1100
committer Stefan Saasen <stefan@saasen.me> 1353116070 +1100
Bump version to 1.6
We use the Commit data type to represent this in our program:
data Commit = Commit {
getTree :: B.ByteString
, getParents :: [B.ByteString] -- zero (root), one ore more (merges) parents
, getSha :: B.ByteString
, getAuthor :: Identity
, getCommiter :: Identity
, getMessage :: B.ByteString
} deriving (Eq,Show)
And a simple Attoparsec based parser to parse the raw commit content:
commitParser :: Parser Commit
commitParser = do
tree <- "tree " .*> take 40
space
parents <- many' parseParentCommit
author <- "author " .*> parsePerson
space
commiter <- "committer " .*> parsePerson
space
space
message <- takeByteString
let author' = Author (getPersonName author) (getPersonEmail author)
commiter' = Commiter (getPersonName commiter) (getPersonEmail commiter)
return $ Commit tree parents B.empty author' commiter' message
Blob
The object of type blob simply contains the content that is tracked by git. This is the actual file content so no parsing or reading is necessary. The blob content will be written as it is to the corresponding file in the working copy.
Tree
Quoting http://git-scm.com/book/en/Git-Internals-Git-Objects for a succinct description of the tree object:
[…] the tree object, which solves the problem of storing the filename and also allows you to store a group of files together. Git stores content in a manner similar to a UNIX filesystem, but a bit simplified. All the content is stored as tree and blob objects, with trees corresponding to UNIX directory entries and blobs corresponding more or less to inodes or file contents. A single tree object contains one or more tree entries, each of which contains a SHA-1 pointer to a blob or subtree with its associated mode, type, and filename.
Looking at an actual tree objects immediately shows that underlying model with the node, object type, SHA1 object-id and filename listed per entry:
[4809] λ > git cat-file -t 19ae5beb4abeea465bfc4aef82fb9373099431c0
tree
[4810] λ > git cat-file -p 19ae5beb4abeea465bfc4aef82fb9373099431c0
100644 blob c364d6f7508e2f6d1607a9d73e6330d68ec7d62a .ghci
100644 blob c3270b6a3e56c40a570beb1185a53ac1cd48ccd3 .gitignore
100644 blob 38781a3632ce2bd32d7380c6678858afe1f38b19 LICENSE
100644 blob ed4a59a07241be06c3b0ecbbbe89bb4f037c0c70 README.md
100644 blob 200a2e51d0b46fa8a38d91b749f59f20eb97a46d Setup.hs
040000 tree 754352894497d94b3f50a2353044ded0f592bbb1 example
100644 blob 2fdb4f2db32695c50a0fcae80bd6dca24e7ba7bd hgit.cabal
040000 tree 58e3ef91a07d0be23ae80f20b8cc18cb7825e1a3 src
100755 blob 0d954128938097e4fc0b666f733b63b27cf14437 test-with-coverage.sh
040000 tree 0b4d3861577e115c29001f38e559440ce27b19b0 tests
Git supports the following modes (from git-fast-import):
100644or644: A normal (not-executable) file.100755or755: A normal, but executable, file.120000: A symlink, the content of the file will be the link target.160000: A gitlink, SHA-1 of the object refers to a commit in another repository. They are used to implement submodules.040000: A subdirectory. Points to another tree object.
The actual tree object content is stored as a set of tree entries that have the following format:
tree = 1*tree-entry
tree-entry = mode SP path NUL sha1
mode = 6DIGIT
sha1 = 20HEXDIG
path = UTF8-octets
E.g.:
100644 .ghci\NUL\208k\227\&0F\190\137A$\210\193\216j\247#\SI\ETBw;?100644 RunMain.hs\NUL\240i\182\&3g\183\194\241-\131\187W\137\ESC\CAN\f\SOHX\180\174
We use the following functions to parse the tree content into a couple of simple data structures:
data Tree = Tree {
getObjectId :: ObjectId
, getEntries :: [TreeEntry]
} deriving (Eq, Show)
data TreeEntry = TreeEntry {
getMode :: C.ByteString
, getPath :: C.ByteString
, getBlobSha :: C.ByteString
} deriving (Eq, Show)
parseTree :: ObjectId -> C.ByteString -> Maybe Tree
parseTree sha' input = eitherToMaybe $ parseOnly (treeParser sha') input
-- from e.g. `ls-tree.c`, `tree-walk.c`
treeParser :: ObjectId -> Parser Tree
treeParser sha' = do
entries <- many' treeEntryParser
return $ Tree sha' entries
treeEntryParser :: Parser TreeEntry
treeEntryParser = do
mode <- takeTill (== ' ')
space
path <- takeTill (== '\0')
nul
sha' <- take 20
return $ TreeEntry mode path sha'
With the ability to retrieve and parse the git objects we can now implement the functionality to check out the files corresponding to a given tree. Our entry point for this is the checkoutHead function:
checkoutHead :: WithRepository ()
checkoutHead = do
repo <- ask
let dir = getName repo
tip <- readHead
maybeTree <- resolveTree tip
indexEntries <- maybe (return []) (walkTree [] dir) maybeTree
writeIndex indexEntries
The first step is to resolve the commit-id that the symref HEAD points to:
readHead :: WithRepository ObjectId
readHead = readSymRef "HEAD"
readSymRef :: String -> WithRepository ObjectId
readSymRef name = do
repo <- ask
let gitDir = getGitDirectory repo
ref <- liftIO $ C.readFile (gitDir </> name)
let unwrappedRef = C.unpack $ strip $ head $ tail $ C.split ':' ref
obj <- liftIO $ C.readFile (gitDir </> unwrappedRef)
return $ C.unpack (strip obj)
where strip = C.takeWhile (not . isSpace) . C.dropWhile isSpace
Note: This is a very simplified version of resolving a ref. refs.c#resolve_ref_unsafe handles loose and packed refs and even the older symlink style refs. For our simple use case this is not necessary as the symbolic ref will have been written by our own code in a previous step.
The second step is to resolve the tree object that this commit points to:
-- | Resolve a tree given a <tree-ish>
-- Similar to `parse_tree_indirect` defined in tree.c
resolveTree :: ObjectId -> WithRepository (Maybe Tree)
resolveTree sha' = do
repo <- ask
blob <- liftIO $ readObject repo sha'
maybe (return Nothing) walk blob
where walk (Object _ BTree sha1) = do
repo <- ask
liftIO $ readTree repo sha1
walk c@(Object _ BCommit _) = do
let maybeCommit = parseCommit $ getBlobContent c
maybe (return Nothing) extractTree maybeCommit
walk _ = return Nothing
extractTree :: Commit -> WithRepository (Maybe Tree)
extractTree commit = do
let sha' = C.unpack $ getTree commit
repo <- ask
liftIO $ readTree repo sha'
Resolving the tree involves reading and parsing the commit and then extracting the tree object-id from the commit.
If the tree lookup is successful we can start traversing that tree depth-first, creating the files in the working copy as we go. This involves creating directories for tree entries (mode 40000) and creating files with the content of the corresponding blob otherwise:
walkTree :: [IndexEntry] -> FilePath -> Tree -> WithRepository [IndexEntry]
walkTree acc parent tree = do
let entries = getEntries tree
foldM handleEntry acc entries
where handleEntry acc' (TreeEntry "40000" path sha') = do
let dir = parent </> toFilePath path
liftIO $ createDirectory dir
maybeTree <- resolveTree $ toHex sha'
maybe (return acc') (walkTree acc' dir) maybeTree
handleEntry acc' (TreeEntry mode path sha') = do
repo <- ask
let fullPath = parent </> toFilePath path
content <- liftIO $ readObject repo $ toHex sha'
maybe (return acc') (\e -> do
liftIO $ B.writeFile fullPath (getBlobContent e)
let fMode = fst . head . readOct $ C.unpack mode
liftIO $ setFileMode fullPath fMode
indexEntry <- asIndexEntry fullPath sha'
return $ indexEntry : acc') content
toFilePath = C.unpack
asIndexEntry path sha' = do
stat <- liftIO $ getFileStatus path
indexEntryFor path Regular sha' stat
Note: While we do handle files modes (644 and 755) we currently ignore the other git modes (symlink and gitlinks (for submodule support)).
After traversing the trees we now have a full checkout of all the files that correspond to the repository snapshot identified by the commit pointed to by the HEAD symref.
Running a git status command in that git repository shows all our newy create files both as untracked and slated for deletion as we haven’t create the git index file yet.
Git index
As our last step we need to create the index file that matches the file status on disk so that git status won’t report any outstanding changes. The index is also called the “staging area” or the directory cache (this should not be confused with the index that accompanies a pack file).
In git the index is used to keep track of changes in the working copy and to assemble the changes that will be part of the next commit.
From the git add man page:
The “index” holds a snapshot of the content of the working tree, and it is this snapshot that is taken as the contents of the next commit. Thus after making any changes to the working directory, and before running the commit command, you must use the add command to add any new or modified files to the index.
Using a simple example we can observe how the index tracks file changes and status.
The exisiting repository tracks a single file LICENSE and has an untracked file README in its working copy:
[4862] λ > git ls-files -scot
? README
H 100644 2831d9e6097f965062d0bb4bdc06e89919632530 0 LICENSE
While the refs point to commit ids, the index file points to the blob object-id for each file. 2831d9 is the object-id for the LICENSE blob:
[4863] λ > git cat-file -t 2831d9e6097f965062d0bb4bdc06e89919632530
blob
At this stage the only objects that this repository contains are one blob, one tree and one commit object:
[4864] λ > tree .git/objects/
.git/objects/
├── 28
│ └── 31d9e6097f965062d0bb4bdc06e89919632530
├── 85
│ └── cbc8d3e3eb1579fc941485b85076d7a97900dd
├── f3
│ └── 8d3a2b142f851984fecc9db9cf34439bb5e47a
├── info
└── pack
The actual index file thus only contains a single entry, the entry for the LICENSE file.
Based on the absence of an index entry for the README file commands like git status or git ls-files -o can deduce that the file is untracked.
The index file entry contains meta data (e.g. modified time, permissions), the file path and the SHA1 of the blob object.
In order to build up or stage the next commit, git creates blob objects when changes (whole file or partial changes via for example git add -p) are added to the index via git add.
This means that commiting the change results in the creation of the required tree objects for the index entries that bind the files to their blob objects and the commit object that has a reference to that newly created tree.
A useful tool for observing changes to the repository (including the temporary creation of lock files) - especialy when the number of objects is large - is using the file system notifications to be notified of changes while running commands (e.g. inotifywait on Linux or spy on Mac OS X):
As can be seen, adding the README using git add (or using git update-index --add) results in the creation of a new blob object file in the .git/objects/ce directory:
[4866] λ > git cat-file -t cebdca635c102a886e8d48c5479b6a7c348c194f
blob
Now the index contains two entries and the README is going to be part of the next commit.
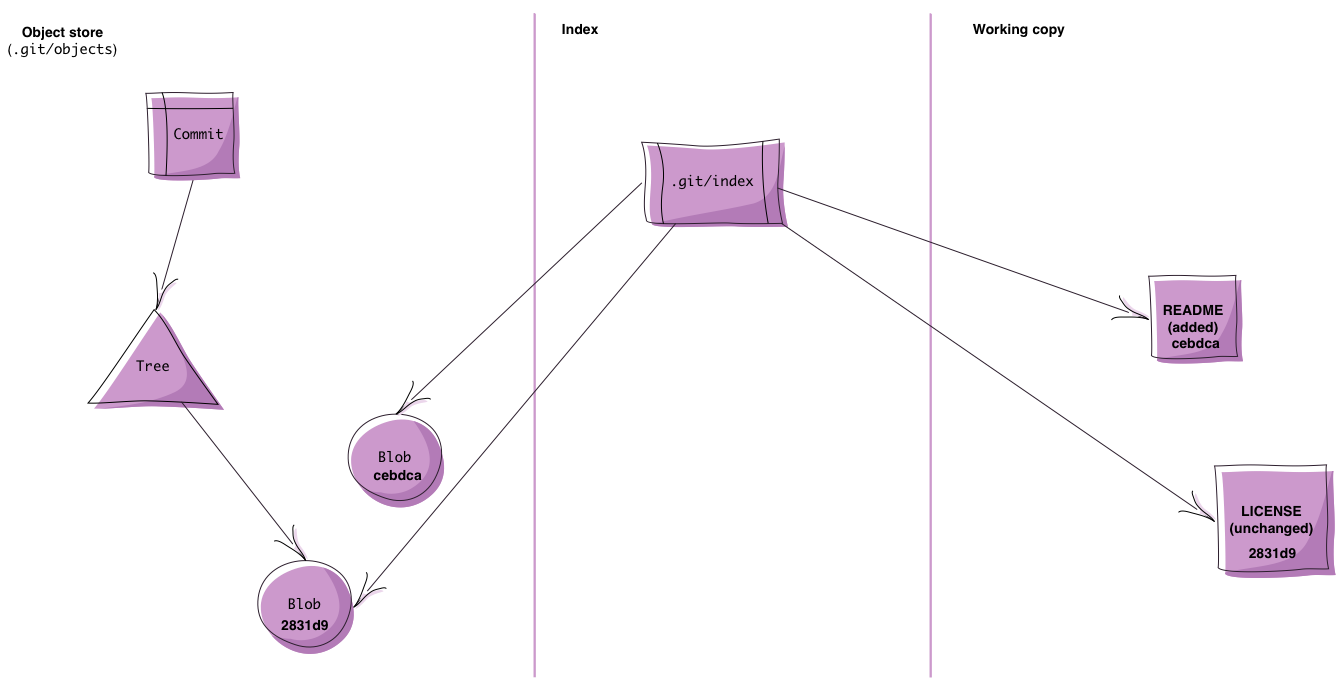
Index format
The format of the directory cache index file itself is described in Documentation/technical/index-format.txt.
The index (stored in .git/index) has a 12-byte index header that is structured in the same way as the pack file header:
- 4-byte signature or magic bytes
'D' 'I' 'R' 'C'(for dircache) - 4-byte version number
- 4-byte number of index entries
This is followed by a number of sorted index entries where each index entry contains stat(2) data (ctime, mtime, device, inode, uid, gid, filesize), the SHA1 object id, a git type (regular file, symlink, gitlink), unix permissions, a couple of status flags and the path and path length of the file the index entry is about (“padded with 1-8 nul bytes as necessary to pad the entry to a multiple of eight bytes while keeping the name NUL-terminated”). The path name includes the directories from the top level directory of the repository.
The git ls-files command can be used to show a detailed view of the index contents:
[5003] λ > git ls-files -s --debug
100644 2831d9e6097f965062d0bb4bdc06e89919632530 0 LICENSE
ctime: 1365582812:0
mtime: 1365582812:0
dev: 16777220 ino: 11640465
uid: 501 gid: 20
size: 8 flags: 0
…
This matches the stat output:
[5004] λ > stat LICENSE
File: "LICENSE"
Size: 8 FileType: Regular File
Mode: (0644/-rw-r--r--) Uid: ( 501/ ssaasen) Gid: ( 20/ staff)
Device: 1,4 Inode: 11640465 Links: 1
Access: Wed Apr 10 21:05:28 2013
Modify: Wed Apr 10 18:33:32 2013
Change: Wed Apr 10 18:33:32 2013
With a way of verifying the index creation the implementation now naturally follows from the observation that the index content is mostly not part of the repository (e.g ctime/mtime, uid/gid) but caches the tree/directory entries so needs to be created while walking the directory tree. The walkTree function that was introduced above does exactly that, while checking out a particular tree (i.e. creating the necessary files) it creates and returns a list of IndexEntry items:
walkTree :: [IndexEntry] -> FilePath -> Tree -> WithRepository [IndexEntry]
walkTree acc parent tree = do
[...]
content <- liftIO $ readObject repo $ toHex sha'
maybe (return acc') (\e -> do
[...]
-> indexEntry <- asIndexEntry fullPath sha'
return $ indexEntry : acc') content
asIndexEntry path sha' = do
stat <- liftIO $ getFileStatus path
-> indexEntryFor path Regular sha' stat
Given the filepath, the git file type (we currently only consider regular files, not symlinks nor gitlinks), the SHA1 object-id and the stat information the indexEntryFor function returns an IndexEntry instance:
data IndexEntry = IndexEntry {
ctime :: Int64
, mtime :: Int64
, device :: Word64
, inode :: Word64
, mode :: Word32
, uid :: Word32
, gid :: Word32
, size :: Int64
, sha :: [Word8]
, gitFileMode :: GitFileMode
, path :: String
} deriving (Eq)
indexEntryFor :: FilePath -> GitFileMode -> B.ByteString -> FileStatus -> WithRepository IndexEntry
indexEntryFor filePath gitFileMode' sha' stat = do
repo <- ask
let fileName = makeRelativeToRepoRoot (getName repo) filePath
return $ IndexEntry (coerce $ statusChangeTime stat) (coerce $ modificationTime stat)
(coerce $ deviceID stat) (coerce $ fileID stat) (coerce $ fileMode stat)
(coerce $ fileOwner stat) (coerce $ fileGroup stat) (coerce $ fileSize stat)
(B.unpack sha') gitFileMode' fileName
where coerce = fromIntegral . fromEnum
As the final step of checking the current HEAD (see above) we write the index to disk:
checkoutHead :: WithRepository ()
checkoutHead = do
repo <- ask
let dir = getName repo
tip <- readHead
maybeTree <- resolveTree tip
indexEntries <- maybe (return []) (walkTree [] dir) maybeTree
writeIndex indexEntries
Writing the index entails sorting the index entries correctly (sorted in ascending order on the name field) and creating the indexHeader:
encodeIndex :: Index -> WithRepository B.ByteString
encodeIndex toWrite = do
let indexEntries = sortIndexEntries $ getIndexEntries toWrite
numEntries = toEnum . fromEnum $ length indexEntries
header = indexHeader numEntries
entries = mconcat $ map encode indexEntries
idx = toLazyByteString header `L.append` entries
return $ lazyToStrictBS idx `B.append` SHA1.hashlazy idx
indexHeader :: Word32 -> Builder
indexHeader num =
putWord32be magic -- The signature is { 'D', 'I', 'R', 'C' } (stands for "dircache")
<> putWord32be 2 -- Version (2, 3 or 4, we use version 2)
<> putWord32be num -- Number of index entries
where magic = fromOctets $ map (fromIntegral . ord) "DIRC"
Using Data.Binary each IndexEntry can be written in binary using the following typeclass definition that follows the index-format specification:
-- see `read-cache.c`, `cache.h` and `built-in/update-index.c`.
instance Binary IndexEntry where
put (IndexEntry cs ms dev inode' mode' uid' gid' size' sha' gitFileMode' name')
= do
put $ coerce cs -- 32-bit ctime seconds
put zero -- 32-bit ctime nanosecond fractions
put $ coerce ms -- 32-bit mtime seconds
put zero -- 32-bit mtime nanosecond fractions
put $ coerce dev -- 32-bit dev
put $ coerce inode' -- 32-bit ino
put $ toMode gitFileMode' mode' -- 32-bit mode, see below
put $ coerce uid' -- 32-bit uid
put $ coerce gid' -- 32-bit gid
put $ coerce size' -- filesize, truncated to 32-bit
mapM_ put sha' -- 160-bit SHA-1 for the represented object - [Word8]
put flags -- 16-bit
mapM_ put finalPath -- variable length - [Word8] padded with \NUL
where zero = 0 :: Word32
pathName = name'
coerce x = (toEnum $ fromEnum x) :: Word32
toMode gfm fm = (objType gfm `shiftL` 12) .|. permissions gfm fm
flags = (((toEnum . length $ pathName)::Word16) .&. 0xFFF) :: Word16 -- mask the 4 high order bits
-- FIXME: length if the length is less than 0xFFF; otherwise 0xFFF is stored in this field.
objType Regular = 8 :: Word32 -- regular file 1000
objType SymLink = 10 :: Word32 -- symbolic link 1010
objType GitLink = 14 :: Word32 -- gitlink 1110
permissions Regular fm = fromIntegral fm :: Word32 -- 0o100755 or 0o100644
permissions _ _ = 0 :: Word32
!finalPath = let n = CS.encode (pathName ++ "\0")
toPad = 8 - ((length n - 2) `mod` 8)
pad = C.replicate toPad '\NUL'
padded = if toPad /= 8 then n ++ B.unpack pad else n
in padded
get = readIndexEntry
The clone command re-implemented
With the last piece in place the git clone command built from the ground up in Haskell can now be executed and works as expected:
[4900] λ > cabal configure
[4901] λ > cabal build
[4902] λ > cabal copy
[4903] λ > hgit clone git://github.com/juretta/git-pastiche.git
remote: Counting objects: 149, done.
remote: Compressing objects: 100% (103/103), done.
remote: Total 149 (delta 81), reused 113 (delta 45)
ssaasen@monteiths:~/temp [0]
[4903] λ > cd git-pastiche/
ssaasen@monteiths:~/temp/git-pastiche (± master ✓ ) [0]
[4903] λ > git status
# On branch master
nothing to commit, working directory clean
ssaasen@monteiths:~/temp/git-pastiche (± master ✓ ) [0]
[4901] λ > git log --oneline --graph --decorate
* fe484e4 (HEAD, origin/master, origin/HEAD, master) Use eval to evaluate either 'tac' or 'tail -r'
* cb48fc5 Use tac by default for reverse output (if available)
What’s missing?
Although the clone works, there are a lot of things missing compared to the git implementation:
- We don’t traverse the graph to see whether it is fully connected
- The creation of symlinks and gitlinks is currently not implemented
- We don’t explicitly verify the commit ids - we do implicitly though as we generate them while storing the files
- And so on…
Conclusion
“Git concepts” puts it succinctly:
Git is built on a small number of simple but powerful ideas.
Being able to rebuilt an (albeit tiny) subset of the git commands while mainly relying on the research of the data structures, file formats and protcols, less so on the actual source is a testament to this statement.3
Footnotes
-
See
transport.c#transport_get_remote_refs↩ -
Although the other way around is certainly easier to get started with. See A birds-eye view of Git’s source code ↩